Cheng Lou introduces a library providing text height without DOM calculation in the hot path, manual line routing, and width-tight multiline UI:
Pure JavaScript/TypeScript library for multiline text measurement & layout. Fast, accurate & supports all the languages you didn’t even know about. Allows rendering to DOM, Canvas, SVG and soon, server-side.
Pretext side-steps the need for DOM measurements (e.g. getBoundingClientRect, offsetHeight), which trigger layout reflow, one of the most expensive operations in the browser. It implements its own text measurement logic, using the browsers’ own font engine as ground truth (very AI-friendly iteration method).
My dear front-end developers (and anyone who’s interested in the future of interfaces):
I have crawled through depths of hell to bring you, for the foreseeable years, one of the more important foundational pieces of UI engineering (if not in implementation then certainly at… pic.twitter.com/BKnwCDIp75
Curious how gzip works? This post by Ian Erik Varatalu explains it step by step.
gzip wraps around huffman coded input, the huffman coded input wraps around lz77 back-references, and the back-references wrap around the actual bytes.
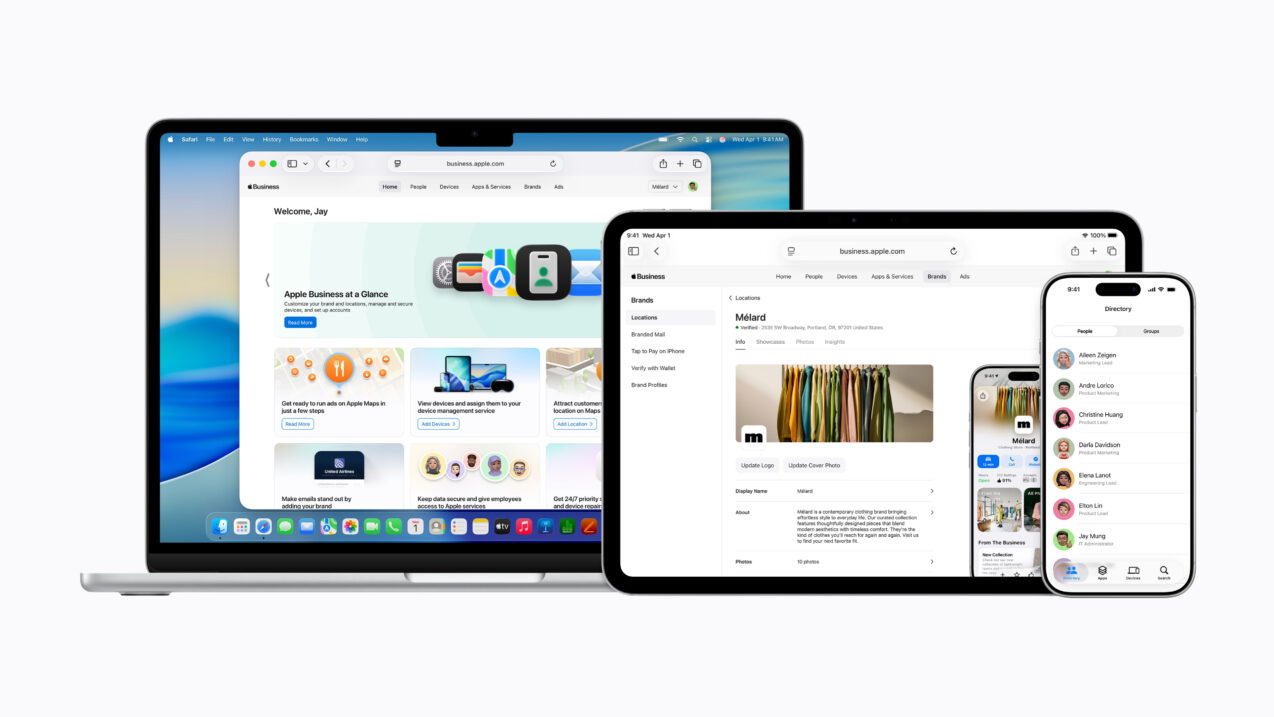
Apple today announced Apple Business, a new all-in-one platform that includes key services companies need to effortlessly manage devices, reach more customers, equip team members with essential apps and tools, and get support from experts to run and grow efficiently and securely.
Here’s some highlights.
Apple Business — a new platform that includes key services companies need to run and grow — will be available April 14. Credit: Apple Inc.
Built-In MDM
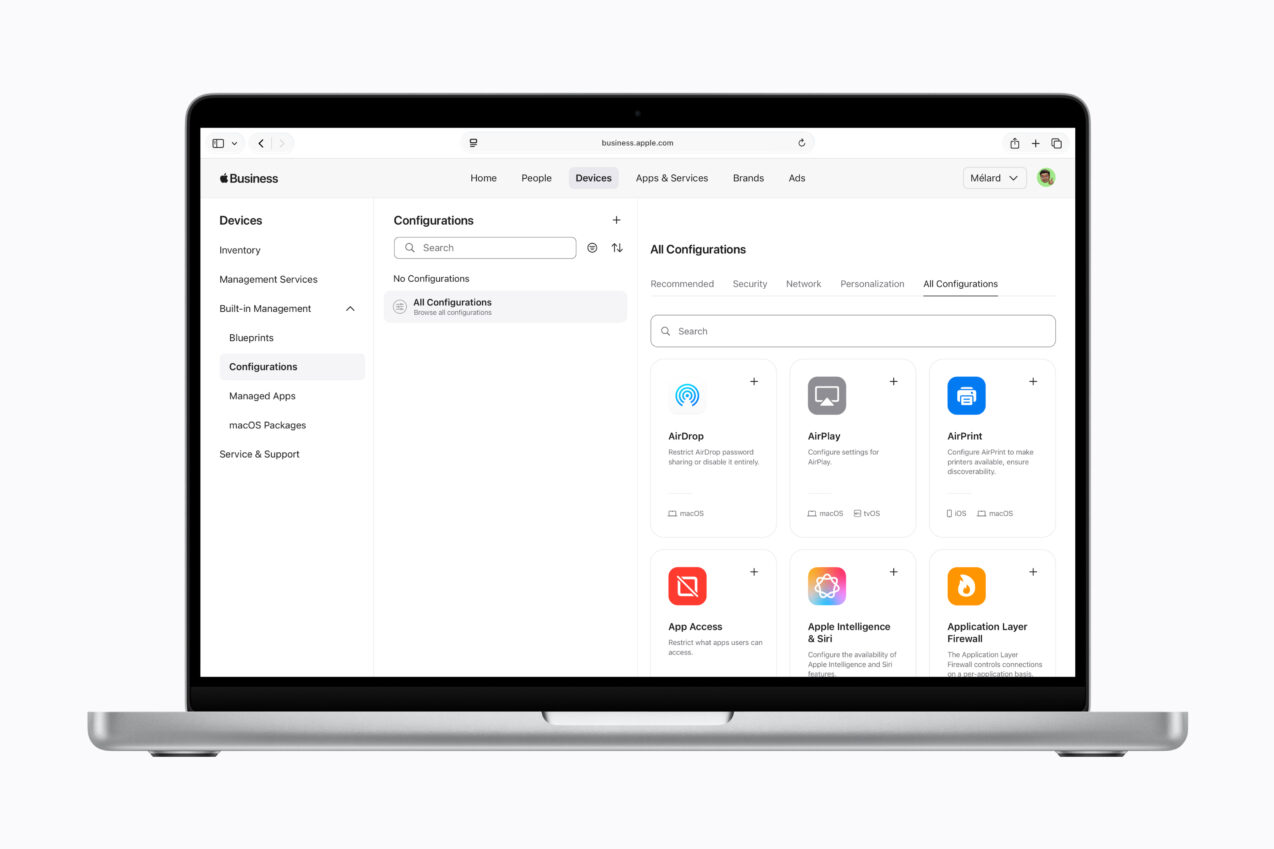
Apple Business offers built-in mobile device management (MDM), facilitating a comprehensive view of an organization’s Apple devices, settings, and more from a single interface. Previously available as a subscription within Apple Business Essentials in the U.S., Apple Business is designed to make IT easy — including for small businesses without dedicated IT resources.
Mobile device management is built in to Apple Business, facilitating a comprehensive view of an organization’s Apple devices, settings, and more from a single interface. Credit: Apple Inc.
Email, Calendar, Directory
Apple Business introduces fully integrated email, calendar, and directory services that are designed to make it seamless to start a new business with a professional identity. Businesses can bring their own custom domain name or purchase a new one through Apple Business, helping founders elevate communication and collaboration. These services streamline operations, with scheduling tools like calendar delegation and a built-in company directory to make it easy for employees to connect with user groups and personalized contact cards.
Brand and Location Features in One Convenient Place
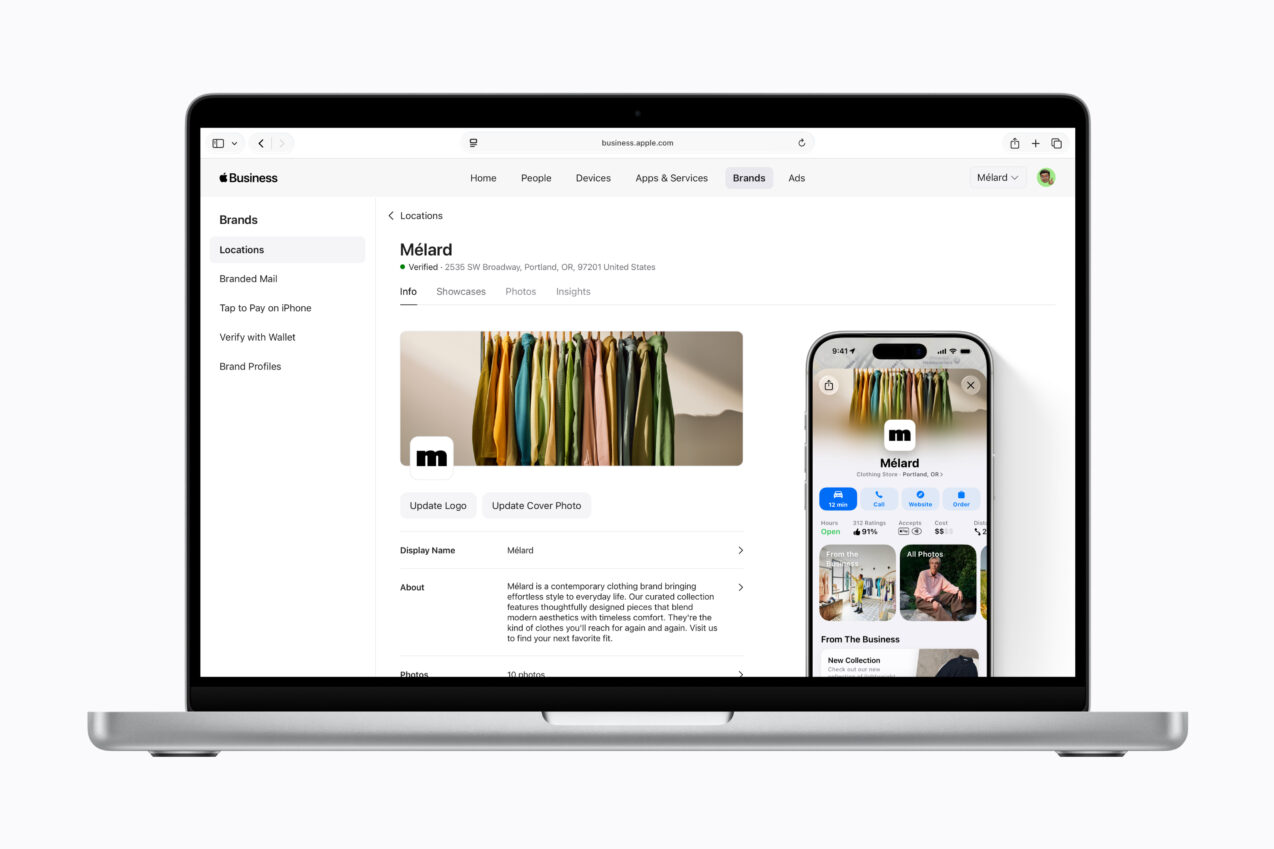
Brand management tools previously available in Apple Business Connect will now be available through Apple Business, making it easier than ever for businesses to set up and manage how their brand and locations appear across Apple services and apps.
With Apple Business, companies can manage their brand name, logo, and key details consistently across Apple Maps, Wallet, and other features and apps. Credit: Apple Inc.
Availability
Starting April 14, Apple Business will be available as a free service in the U.S. and 200+ countries and regions to new and existing users of Apple Business Connect, Apple Business Essentials, and Apple Business Manager.
Apple Business Essentials, Apple Business Manager, and Apple Business Connect will no longer be available once Apple Business launches. Business Essentials customers will no longer be charged their monthly service fee for device management after April 14. Existing Business Connect data — including claimed locations, place card information, photos, organization information, account details, and more — will automatically migrate to Apple Business at launch.
Worktrunk is a CLI for git worktree management, designed for running AI agents in parallel.
AI agents like Claude Code and Codex can handle longer tasks without supervision, such that it’s possible to manage 5-10+ in parallel. Git’s native worktree feature give each agent its own working directory, so they don’t step on each other’s changes.
But the git worktree UX is clunky. Even a task as small as starting a new worktree requires typing the branch name three times: git worktree add -b feat ../repo.feat, then cd ../repo.feat.
In addition to improving common tasks like switching and cleaning up worktrees, Worktrunk provides workflow automation too:
Hooks — run commands on create, pre-merge, post-merge, etc