
I make tools to help people write great software. I am a software engineer at Apple helping businesses succeed.
Previously, I led the platform team for Yahoo Mail’s web application which is relied upon by millions of people every day around the world.
-
RepoBar ↗
RepoBar keeps your GitHub work in view without opening a browser. Pin the repos you care about and get a clear, glanceable dashboard for CI, releases, traffic, and activity right from the macOS menu bar.
Works with GitHub Enterprise. I’ll be trying this out when I’m back to work next year.
RepoBar signs in via browser OAuth and stores tokens securely in the macOS Keychain. It supports both GitHub.com and GitHub Enterprise (HTTPS). No tokens are logged.
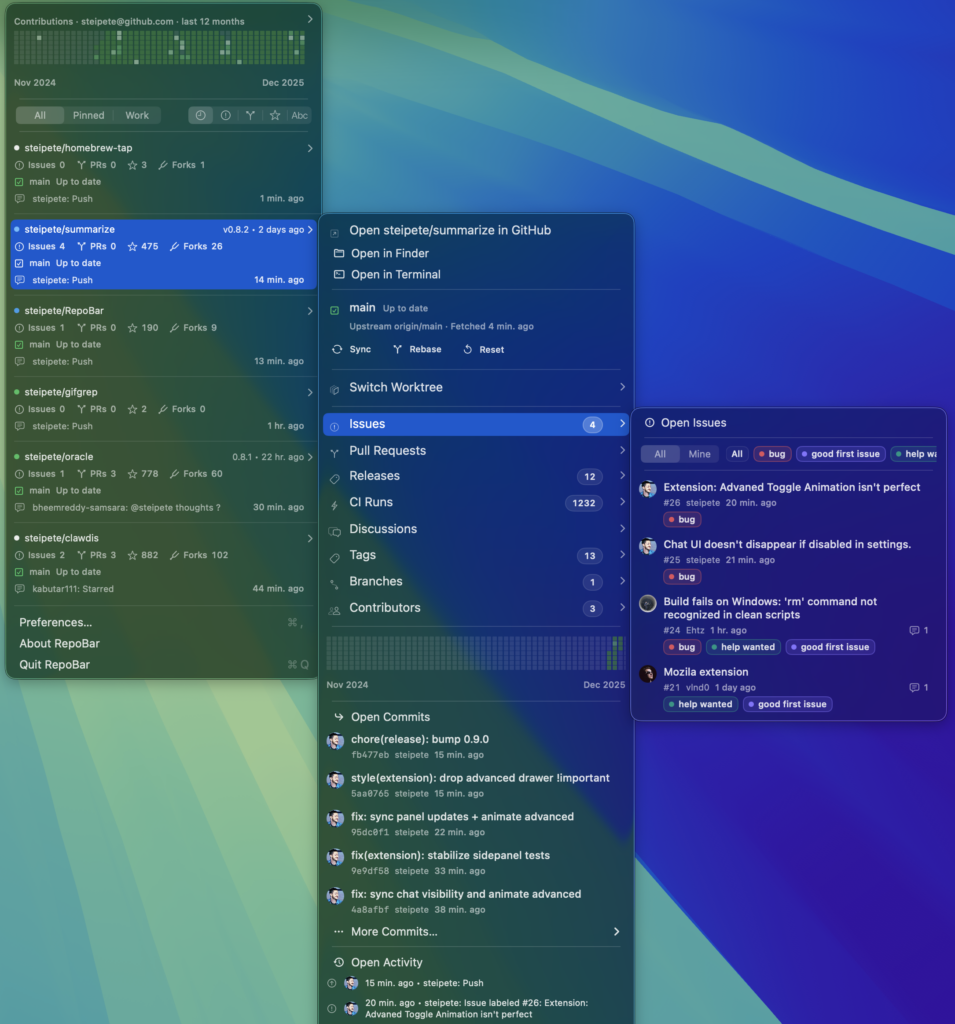
Screenshot courtesy of Peter Steinberger -
Vite 8 Beta: The Rolldown-powered Vite ↗
The Vite Team:
We’re excited to release the first beta of Vite 8. This release unifies the underlying toolchain and brings better consistent behaviors, alongside significant build performance improvements. Vite now uses Rolldown as its bundler, replacing the previous combination of esbuild and Rollup.
Rolldown supports the same plugin API as Rollup and Vite which keeps most existing plugins working.
These Rolldown-powered optimizations are not yet ready but they are very interesting:
- Raw AST transfer. Allow JavaScript plugins to access the Rust-produced AST with minimal overhead.
- Native MagicString transforms. Simple custom transforms with logic in JavaScript but computation in Rust.
-
Critical Security Vulnerability in React Server Components ↗
The React Team:
On November 29th, Lachlan Davidson reported a security vulnerability in React that allows unauthenticated remote code execution by exploiting a flaw in how React decodes payloads sent to React Server Function endpoints.
Even if your app does not implement any React Server Function endpoints it may still be vulnerable if your app supports React Server Components.
This vulnerability was disclosed as CVE-2025-55182 and is rated CVSS 10.0.
The security fix was implemented in a pull request to patch FlightReplyServer. Upgrade now if you’re affected.
A fix was introduced in versions 19.0.1, 19.1.2, and 19.2.1. If you are using any of the above packages please upgrade to any of the fixed versions immediately.
If your app’s React code does not use a server, your app is not affected by this vulnerability. If your app does not use a framework, bundler, or bundler plugin that supports React Server Components, your app is not affected by this vulnerability.
Some React frameworks and bundlers depended on, had peer dependencies for, or included the vulnerable React packages. The following React frameworks & bundlers are affected: next, react-router, waku, @parcel/rsc, @vitejs/plugin-rsc, and rwsdk. -
Anthropic acquires Bun as Claude Code reaches $1B milestone ↗
Bun is used as the runtime for Claude Code. Today it was acquired by Anthropic.
We’ve been a close partner of Bun for many months. Our collaboration has been central to the rapid execution of the Claude Code team, and it directly drove the recent launch of Claude Code’s native installer. We know the Bun team is building from the same vantage point that we do at Anthropic, with a focus on rethinking the developer experience and building innovative, useful products.
Congratulations to Jarred Sumner and the Bun team. Here he describes how the acquisition happened:
We’ve been prioritizing issues from the Claude Code team for several months now. I have so many ideas all the time and it’s really fun. Many of these ideas also help other AI coding products.
A few weeks ago, I went on a four hour walk with Boris from the Claude Code team. We talked about Bun. We talked about where AI coding is going. We talked about what it would look like for Bun’s team to join Anthropic. Then we did that about 3 more times over the next few weeks. Then I did that with many of their competitors. I think Anthropic is going to win.
I had the privilege to walk with Jarred a couple weeks ago during a rainy day at Apple Park. He’s very smart. I’m thrilled to hear he’s getting all the fuel needed to build great tools.
-
We need to demand better ↗
Matt Mahan, the mayor of San Jose, California:
Without a doubt, California is still the most innovative state. But we won’t stay that way unless we face facts. And they are grim.
We have the nation’s highest poverty rate and highest unemployment rate. Our energy costs are the highest in the continental United States. Nearly half of America’s unsheltered homeless people live in California. And all the while, Californians bear the nation’s second-highest state and local tax burden and must reckon with hundreds of billions’ worth of unfunded pension liabilities and deferred maintenance on public infrastructure in the years ahead.
As a mayor, I have the responsibility of addressing these challenges. My constituents don’t accept excuses, nor should they. In San Jose, we have not waited for Sacramento and have invested in quick-build housing solutions and are reducing our unsheltered homeless population. We are using new technologies and old-fashioned, street-level policing to become the safest big city in America again. We have embraced the responsible use of AI to make government more effective, from spotting potholes before they form to helping buses run faster.
[…]
On a city-to-city level, we’ve seen the benefits of close collaboration. […] However, statewide, Sacramento and local governments are not collaborating in a way that yields the best results for the public.
The most pressing example is homelessness. Last year, when 68% of Californians voted yes on Proposition 36, they agreed that those suffering from severe addiction should be required to go to treatment if they steal to buy drugs. This policy would save thousands of lives, billions of dollars, and help people get the treatment they need to escape the streets. Where is it? Sacramento refuses to implement it.
California has seen nearly as many people die on our streets in the last 12 years as the nation lost in the Vietnam War, with most being overdose victims. A commonsense bill allowing — not requiring — dedicated sober living spaces for the homeless was just passed by the Legislature. Where is it? The governor vetoed it.
Caltrans takes 4-6 weeks to approve clean ups for freeway ramps and underpasses which leads to large buildups of trash and suffering. The state cannot maintain their land. San Jose is stepping up by making a deal with the governor to delegate authority to the City to bring help and accountability to neglected state land in San Jose.
Energy costs are a serious problem. California energy costs have gone up 34% since 2019 while Nevada fell 8% and Arizona fell 3%.
Follow
Featured Blog Post
-
Starting at Apple
I will help small businesses succeed by building Apple Business Essentials — a product which brings together device management, 24/7 Apple support, and iCloud storage into flexible subscription plans. More →