How much energy should we invest into getting “just this next bug fixed and working” versus taking a sip of tea and then you should change your approach or change your job?
Mayor Matt Mahan wants to end homelessness in San Jose neighborhood by neighborhood.
When it comes to my proposal that we use a brief, targeted interaction with the criminal justice system to compel those who repeatedly refuse private shelter to instead engage with treatment, we’ve been talking a lot lately about the moment of accountability. The moment where things get so bad that we need to take action to help those suffering and the broader community. But we don’t talk a lot about the many moments that come before and the many moments that will come after because of our action at this critical juncture.
So let’s start from the beginning.
Matt Mahan is leading the way. Others need to step up. The County of Santa Clara has a responsibility to build out treatment beds. Judges need to make wise judgements. I hope this policy will free people from addiction and suffering. Go read the Mayor’s plan. Let’s make it our reality together.
RSC is mindbending, I won’t lie. Sometimes you have to think inside-out. But personally, I think RSC is awesome. The tooling is still evolving but I’m excited for its future. I hope to see more technologies thoughtfully blending the boundaries.
Ryan Florence introduces Jacob Ebey’s latest work to bring RSC to React Router.
We’re leveraging Parcel’s RSC support to help us figure out what React Router looks like when RSC is a first-class bundler feature. You’ll note in the preview template there’s a little Parcel plugin for routes.ts to button it all up and it’s pretty small. The effort to port to other RSC-native bundlers in the future should be equally minimal.
By targeting RSC-native bundlers like Parcel, we’re also helping to guide the direction of Vite’s official RSC support. Hiroshi Ogawa is currently working publicly on Vite RSC support and using React Router’s RSC APIs in Vite to validate their approach. By sharing our early RSC work publicly, we can help ensure that we’ll be ready once Vite RSC support finally lands.
This is very exciting for us: both React’s and React Router’s full feature sets will soon be usable with very little effort with any bundler, any JavaScript runtime, and any server!
There’s also a great section on batching and caching:
A couple major concerns with the RSC architecture are N+1 queries and over-fetching. Both are very easy to do when components can fetch their own data. We saw it happen in many Hydrogen v1 apps and it tanked performance to unacceptable levels.
If you’re not familiar, the first version of Hydrogen used RSC before abandoning it. Ryan proposes a new generic concept for solving this problem using batch-loader:
import{batch}from"@ryanflorence/batch-loader";// Async context to load data from anywhere in the appletcontext=newAsyncLocalStorage<ReturnType<typeofcreateLoaders>>();// React Router middleware to provide the context to the appexportconstdataMiddleware: MiddlewareFunction<Response>=async(_,next)=>{// create batchFunctions for just this requestletbatchFunctions={movie:batch(batchMovies),actor:batch(batchActors),};returnnewPromise((resolve)=>{context.run(batchFunctions,()=>{resolve(next());});});};// load function to be used anywhere, especially in componentsexportfunctionload(){returncontext.getStore() as ReturnType<typeofcreateLoaders>;}
Ryan is looking to bring this kind of concept into React Router.
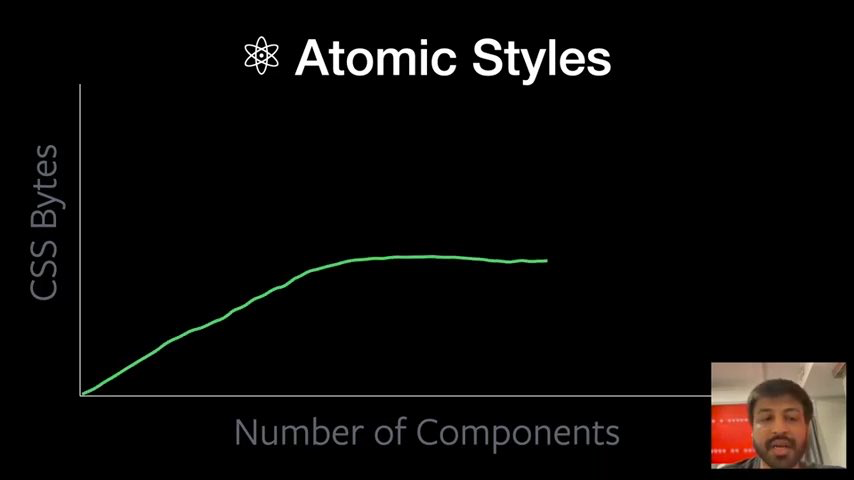
Atomic CSS is a great idea. You can keep CSS size growth sub-linear in large applications with a lot of components.
Co-locating styles with React components is a great idea too. You can keep the styles you need right next to the component.
Many folks implement these ideas with Tailwind.
It’s fine if you like Tailwind. But Tailwind is not CSS — it’s a DSL of class names to apply styles. You need to learn Tailwind. Your designers need to learn it. Keeping your Tailwind DSL synced up with tools like Figma which exports CSS introduces friction and conversion.
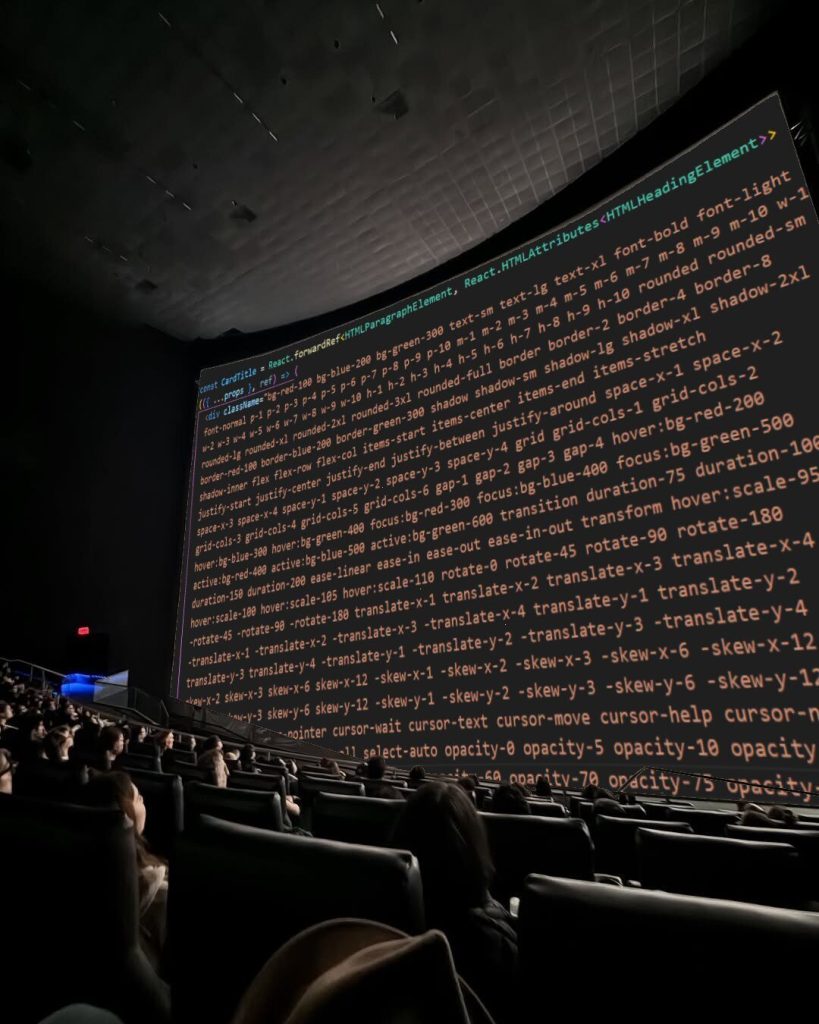
And you’re going to need a larger monitor. Courtesy of @RhysSullivan, here’s a single div styled with Tailwind in IMAX 70mm:
Single div styled with Tailwind on IMAX 70mm. Image credit: @RhysSullivanVia X
Meta built StyleX to solve these problems. Yahoo Mail built a very similar system internally over 6 years ago where you write CSS as JavaScript objects co-located with your React components. Your CSS looks like CSS.
Yahoo Mail’s entire CSS was under 45 KB gzipped and it’s a huge application. It was so small we simply inlined it into the SSR HTML.
I hesitate to recommend StyleX for all projects. The ergonomics and open-source build tooling need refinement. Surely Meta has internal tools they use for building StyleX which are better than the open-source tools.
But the idea of StyleX is fantastic. I believe the public open-source implementation will get there eventually. The ideas are too good.